郑晓娜 等
一、目前市场反馈机制存在的问题
随着新技术的快速应用普及、数据的爆发以及信息流动更加快速,越来越多的新型商业模式出现并迅速发展,如新零售、无人商店、全渠道零售等。新型商业模式的催生带来数据非结构化、多维度的变化趋势和对信息时效性的更高要求。1)所谓时效性,是指信息仅在一定时间段内对决策具有价值。相较于传统的商业模式,新型商业模式更为强调这一点。例如,在全渠道零售模式下,消费者可以选择在线上或线下任意一个渠道体验、购买和取货。该模式在拓宽消费者的购买渠道和体验渠道的同时,也对信息的时效性提出了更高的要求:渠道管理者需要根据消费者的不同选择柔性制定库存策略,及时发送补货信息,动态形成需求预测。2)所谓非结构化,体现在新型商业模式下的数据不仅仅是以固定格式或有固定长度的形式出现(即,结构化数据的形式,例见表1),而更多地表现为语音、图像、无固定格式的文本,如消费者对于某商品的评论等多种形式,以上不定长或无固定格式的数据被定义为非结构化数据。3)此外,随着获取信息渠道的多样化和生活水平的提升,消费者不再单一地关注产品价格,而是更为广泛地关注质量、品牌、口碑、售后服务等更多维度的信息,体现出数据向多维度发展的趋势。不难看出,新型商业模式下的数据形式纷繁复杂,其特有的性质和对时效性、非结构化、多维度的要求将对数据分析和处理方法提出更高挑战。
然而,在经典和通用的方法里,多采用统计学和计量经济学的传统方法对行业情况进行分析,采用财务报表分析来衡量公司的经营和管理情况。通过分析发现,传统方法已经显然不能满足新型商业模式的要求。尤其在衡量和表达两个核心经济主体:市场和公司时,出现了越来越明显的偏离和延迟,主要体现在如下三个方面:
第一,滞后性。传统方法以处理静态数据(即,在很长一段时间内不会变化的数据)为主。难以对快速变化的市场和公司经营情况进行统计分析,出现了公司难于了解市场、政府难于分析行业、消费者难于了解商品等情况。由于决策往往对时效性要求很高,传统统计分析的结果逐渐成为参考因素之一。在整个决策过程中,人的经验、更多的信息和更加实时反馈的机制,成为关键因素。
第二,片面性。传统方法侧重于处理结构化数据,难以处理非结构化的语音、图像、无固定格式的文本等数据;受制于工具和方法,传统方法难以处理数据全体,而更多地只能通过在全体中抽取一部分作为样本,进行分析。可以说,传统方法对传统经济形态的表达更为准确,对于共享经济、电子商务等新型商业模式的表达欠缺。因此,传统的方法不可避免地产生了偏见和片面性。
第三,降维性。在市场和公司的长期交互中,逐渐形成了以价格为主体的交易机制。价格综合体现了商品的质量、品牌、口碑、售后服务等多维度的信息,起到了降维的作用。在传统的方法中,也选择价格作为重要指标,辅以交易量、利润率等指标,试图从这些降维后的指标中还原复杂经济行为中各个决策环节。在这个过程中,信息经历了降维和还原的过程,消费者的意见、态度等关键信息却在这个过程中流失,难以还原。
时至今日,以电子商务为代表的经济体已经具备高度数字化的特点,可以很大程度地保留经济行为(例如,消费者的消费行为、企业的生产和营销行为等)的全过程数据。同时,电子商务公司推出了以“消费者线上评价、客服在线互动”为主要形式的市场反馈机制,建立起消费者和电商企业的互动关系,实现了“生产经营在市场产生信息,并反馈到生产经营中去”的设计初衷。上述两个机制虽然在具体品类的商品交易过程中得到广泛应用并取得良好效果,但对市场和公司进行综合分析时,仍然存在片面性和降维性的问题。
上述分析揭示了新型商业模式下的企业普遍面临的难题:如何在较小的成本代价下,最大限度地保留信息的全貌、抽取有效信息,并实现对市场的快速响应和反馈?
本文基于人工智能技术,提出了一种实时市场反馈机制。该机制可以在较小的资源代价下,训练得到准确率较高的预测模型,做到对市场数据的全貌获取、抽取有用信息,并实现对决策的及时支持和对市场的快速响应。
二、基于人工智能技术的实时市场反馈机制
近年来,出现了大量基于商品评价、基于大数据处理方法的市场反馈机制的研究,受限于自然语言处理能力的不足,以及因为样本数据过少所导致的片面性,对市场和公司的分析表达尚未取得有力的进展。本报告采用了基于自然语言处理和行业知识图谱的人工智能技术,建立了一种实时的市场反馈机制。具体的思路是:使用便捷和受众广泛的反馈渠道,综合海量的网络评价数据、舆情数据、客服数据、调研问卷数据,采用人工智能技术进行分析,并与企业的经营情况和关键指标进行关联匹配,以期为其建立实时的市场反馈机制,服务于企业和行业的综合研判分析。
本文中研究的基本技术框架如图1所示。
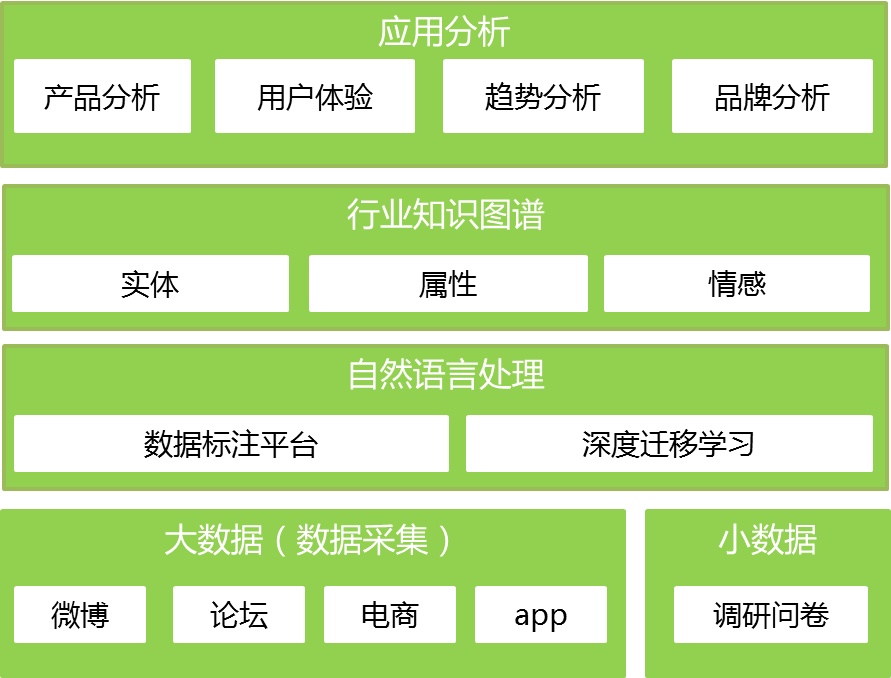
图1. 基本技术框架
该框架涉及数据采集技术、自然语言处理技术、知识图谱等大数据和人工智能技术,从收集的数据中自动化抽取出行业知识,再进行各种应用层的市场分析。采用图1中自底向上的分析过程,具体分析方法如下:
第一,数据采集:首先设定分析的目标,可以是企业的品牌、产品品类或者具体的产品,根据分析目标设计互联网公开数据采集的关键词以及数据采集的渠道,包括微博、论坛、电商、APP等等,并设计对应的调查问卷。本课题将采用北京百分点信息科技有限公司成熟的数据采集软件来获取互联网公开数据,同时采用该公司的“乐调查”软件来获取调研数据。
第二,自然语言处理:采集回来的数据中包括大量的非结构化文本数据,需要结合自然语言处理技术。即,从文本中自动化地抽取出分析的对象(品牌、品类或者具体的产品)、其对应的属性(某一方面或者某一话题),以及消费者对该属性的情感(包括“正面”“中性”和“负面”)。例如针对文本“华为P30Pro的拍照功能真的很清晰”,抽取出来的实体就是“P30Pro”、属性是“拍照功能”、属性上的情感是“正面”。
在传统的深度学习技术下,要让机器能够从海量文本中智能抽取出这些信息,就需要大量带有结果的训练数据来“训练”并“教会”机器如何从非结构化文本中抽取所需结果,训练数据的获取难度非常大且训练效果不佳。鉴于此,本研究首先基于大量容易采集和获得的语料(包括维基百科、百度百科、微博、论坛等)训练出一个通用的模型,然后再将该模型迁移到具体的自然语言分析任务中。由于通用模型已经具备较好的信息处理能力,因此只需再通过少量的训练数据就能达到更为理想的效果。该方法被称为深度迁移学习,既解决了训练数据获取难的问题,又保证了训练效果。事实证明,所需要的训练数据量不到深度学习的1%,但在实体抽取、属性抽取和情感分类上的准确率都能达到85%以上。
第三,行业知识图谱:通过自然语言处理后,即可得到行业知识图谱的基本组成要素:实体、属性和情感。行业知识图谱的优点在于围绕市场的实际需求建立完整的知识体系,把握住用户对于企业品牌和产品的心理体验,为企业提供有洞察价值的市场决策支持。
第四,应用分析:基于行业知识图谱,可以进行各种市场分析,包括品牌分析、产品分析、用户体验分析以及趋势分析等等,为企业的营运决策提供有效参考。就产品分析而言,可以根据行业知识图谱分析出企业的产品相比市场上竞争产品的各种优劣势,这代表着消费者真实的市场声音,对于下一代产品的改进有非常重要的指导意义。另外,趋势分析对于企业的市场分析也很重要,通过行业知识图谱,可以及时捕获到产品特性的新热点,例如对于咖啡企业来说,发现某种新口味的咖啡突然被讨论的声量特别大,企业及时抓住趋势,推出对应的新品,这样就能在激烈的市场竞争中,避免落伍被淘汰。
三、现实应用—以某品牌牙膏为例
由于生活节奏的变化,加之熬夜、压力大等因素,人们经常出现上火的症状,如牙龈肿痛和口腔溃疡。因而在选购产品时,消费者会关注产品的清火效果。某品牌牙膏希望了解消费者对其牙膏清火效果的口碑,针对该项目,本研究团队选取电商网站、小红书、知乎等网站数据,采集约40万条口碑评价文本数据。
在以上40万评价文本数据中,涉及18个主要的清火产品品牌。结合该牙膏品牌厂商的述求,本研究团队对18个品牌及每个品牌的5种产品(牙刷、普通牙膏、电动牙刷、漱口水、牙线)进行总体口碑评价分析,设计了一个三级标签结构:一级(口腔护理类);二级(18个品牌名称);三级(每个品牌的5种产品)。之后,对特定品牌的多种产品进行情感标注。例如,某消费者针对某品牌给出“这个牌子的电动牙刷不错,漱口水效果一般”这一评价,则标注电动牙刷这一产品对应的情感为“正面”,标注漱口水这一产品对应的情感为“中性”。
将采集并标注后的数据通过深度迁移学习算法进行训练,训练完成后的模型可以预测出不同品牌、产品、维度的整体评价。表1列举了部分维度和对应特点描述。
表1. 清火产品的部分维度和对应特点描述
维度 |
特点描述 |
症状Symptoms |
口气 溃疡 口角长泡 肿痛 出血 炎症长痘 便秘 |
场合 Occasions |
火锅 水果 小龙虾 油腻食物 辛辣食物 重口味烧烤 春天夏天秋冬天熬夜 加班 压力大 冷水刷牙 生活不规律 |
方法 Solutions |
牙膏 食疗 药物 口腔护理产品 理疗 足贴 |
牙膏功效 TP’s Benefit |
除口气 除溃疡 去红肿 止血 固齿 防蛀 多效 美白 去渍 抗色素沉淀 去牙菌斑 去结石 洁齿 护龈 护牙釉 抗敏感 去菌 |
成分 Ingredient |
|
安全性 Safety |
天然 无添加 可食用 无糖 |
包装 Package |
压泵式 管状 站立式 盖子 |
产地 Origin |
物流 客服 包裹 正品 |
服务 Service |
|
价格 Price |
价格 促销 |
确定维度后,通过同样的方法训练模型并进行预测,形成相应评价指标。企业主要关心的指标包括:
(1) 评论数(BUZZ):该指标体现了消费者对于产品特定维度的关心程度。评论数越多,说明消费者对该产品维度更关心。
(2) 好评度(Positive Sentiment Rate,简称PSR):该指标体现了消费者对产品特定维度的体验好感度。产品好评度指数越高,口碑形象越好。具体计算公式如下:
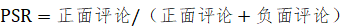 ;
;
(3) 净喜好度(Net Sentiment Rate,简称 NSR):净喜好度和好评度都反映了消费者对某产品特定维度的好感度。不同点在于,其在好评度的基础上进一步体现了负面评论的影响。具体计算公式如下:
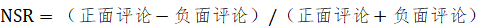 。
。
文本处理完成后,根据各品牌、各产品、各维度的分析结果,构建出行业品牌、产品关于清火相关分析维度的分布图谱(可参见图2、图3),该图谱体现了不同维度产品、品牌的口碑优劣势。通过图谱了解市场评价有助于企业更清晰地认识产品的竞争力和不足:一方面,图谱可以帮助企业形成品牌优势,保持竞争力;另一方面指导企业更好地投入产品创新研发,弥补产品弱势,满足市场需求。
针对本案例,图2展示了具体结果(由于数据敏感,精确数字在此报告中被隐去)。从图2可以看出,针对清火方法(Solutions)的讨论量最多,而上火症状(Symptoms)的负面评论量相对最大(-64%)。可见,1)若干上火症状是导致消费者产生负面评论的关键。2)消费者对于清火方法的关注程度相对最高,说明消费者也试图通过一系列的外在手段达到清火的目的。以上两点,说明清火功效的牙膏确实具有较高的市场需求,并为牙膏品牌商推出相关清火系列产品提供了理论支持。
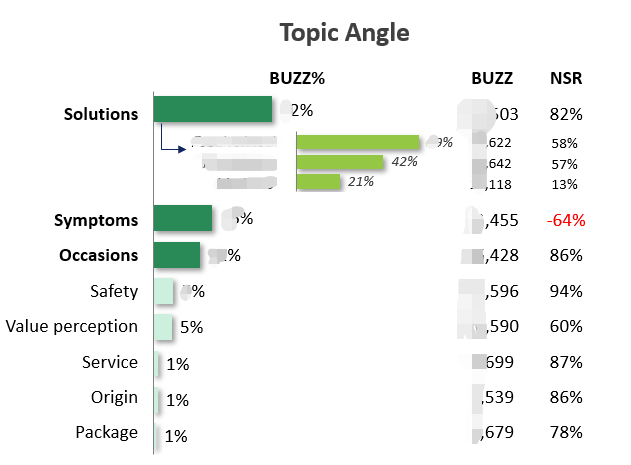
图2. 评论维度的评论数(BUZZ)与净喜好度(NSR)
在这个项目中,除了对不同品牌、产品、维度进行情感正负面分析以外,我们对用户经常提及的问题点也进行了归纳和统计,统计出不同问题点提及最高的问题内容,如图3所示。例如对于症状(Symptoms),最多被提及的症状占比26%;而最多被提及的场合占比35%。借助该研究技术,牙膏品牌商可以更为准确地获取消费者上火的本质原因,把握产品的创新研发方向和营销方向。
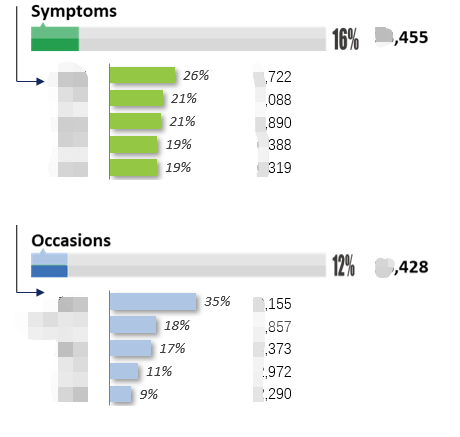
图3. 用户在重点维度评论的问题点
当然,掌握产品维度喜好统计结果和行业知识图谱有时也不足以满足客户所有需求。基于分析结果,对重点维度进行深度原始数据挖掘,总结出每种维度用户最不满意的方面和问题,是分析结论的另一重要部分。
四、结论
新型商业模式的催生具有对信息时效性的更高要求并带来数据非结构化、多维度的变化趋势。然而,在新型商业模式的背景下,传统的数据采集方法出现了明显的滞后性、片面性和降维性。找到一种行之有效的数据采集和处理方法,是应对技术革新、支持企业决策、形成企业竞争力的重要举措。
基于自然语言处理和行业知识图谱的人工智能技术弥补了传统数据采集方法和分析方法的缺陷。通过互联网数据的采集和文本的分析处理,结合深度迁移学习的自然语言分析模型,构建行业产品知识图谱,可以帮助企业掌握市场反馈,了解产品问题,为企业改进其自身产品提供明确目标,为其产品研发、市场分析提供重要的指导,从而提高决策效率。
作者介绍:
郑晓娜 bat365在线平台网站光华管理学院
苏海波 北京百分点信息科技有限公司
李亚博 北京百分点信息科技有限公司







