【编者按:某年某月某一天,光华管理学院商务统计与经济计量系系主任王汉生教授与同学们开会,聊到个人征信问题,大家掏出手机,查询某支付软件上自己的信用分,结果不比不知道,王教授的分数居然比同学们都低!别人受刺激会头抢地,教授被“惹毛”怎么办?写Paper!于是就有了下面这篇文章(本文摘选自王汉生教授微信“狗熊会”)】
我个人认为“芝麻信用分”是互联网征信这个行业里,可圈可点做得很不错的一个产品。但就像一个普通人一样,再优秀的个体,都会有成长的困惑与烦恼,尤其是当他长得快的时候。“芝麻信用分”所表现出来的问题,是互联网征信整个行业普遍存在,而被忽视的一个普遍问题。那就是缺乏对征信误差(Credit Scoring Error)的深刻认识。造成的后果就是:征信泛滥。不分对象,不分场景,任何一个机构,都敢在大数据的幌子下,给人打分。那么,什么是征信误差?我不知道这个名词在过去的文献中是否存在过。如果没有,请原谅王老师自己瞎编了这个词。主要想说明下面这么一个道理。假设一个人的真实信用情况是Z,这是一个任何人都看不见的最真实信用情况。如果我们知道了Z,世界上就不再有“征信”这个问题。但是,信用评估机构(例如:芝麻)看到了一系列的,可能同Z相关的指标(例如:消费习惯、收入状况、教育程度等)。我们把这所有的相关性指标用一个向量X表示。这里,依赖于X中采集了多少可见的指标,它的维度有可能很高。那么,征信的核心问题就是:要通过看得见的X,推测看不见的Z。
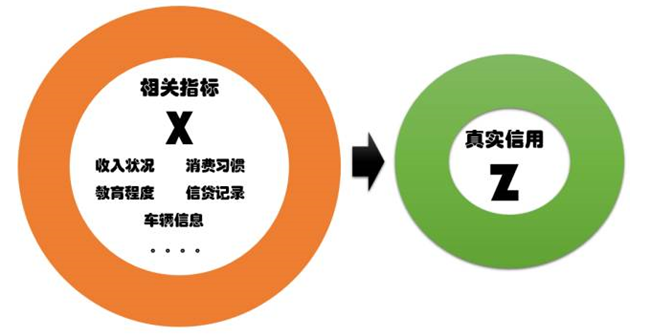
但是,给定X,就能精确地知道Z了吗?当然不可能。我自己都说不清楚我的Z是多少,你怎么知道?我借了隔壁老王100元,还?还是不还?可能懒得还,我俩老熟了,这点钱还要还。我要是借了100万呢?我要是借了100亿呢?这说明什么?这说明同一个人的Z,可能会随着场景的不同而不同。这又说明什么?这说明即使本人都说不清楚自己的Z是多少,更何况一个征信机构。但是,征信机构会通过X,以及大量用户真实的信用行为,学习出一个模型来。然后,通过这个模型去猜测真实的信用Z。数学上把这个猜测记作:Z*=f(X)。没错,Z*就是那个征信得分(例如:芝麻信用分),它就是X的一个函数。用统计学的语言讲,Z*是对真实信用Z的一个估计量(Estimate)。既然Z*是一个估计量,那么他就不会100%准确。他同真实的信用Z之间,会有一个偏差,而这个偏差就是我所定义的“征信误差”(Credit Scoring Error),即:CSE=|Z*-Z|。
我们对征信误差的期待是什么?当然是越小越好。怎样才能让CSE变小呢?样本量会有帮助吗?有,但是帮助不大。例如:我告诉你全世界每一个人的性别(木有其他信息),这个样本量够大了把?但是,对征信而言,帮助极其有限。因为,对于征信而言,性别不是一个特别重要的指标,而且这还是唯一的指标。所以,真正的可以减少征信误差的方法是:增加X,让X的信息更加丰富,让X的维度变得更高。例如:以前X里面只有淘宝的数据,现在可以考虑增加京东的;以前X里面只有收入水平,现在可以考虑增加教育程度;以前X里面只有消费数据,现在可以考虑增加社交信息。只有增加高质量的X,才可以降低征信误差,从而降低信贷风险。这就难怪,几乎所有征信企业的高管,都忙于拓展数据源,丰富自己的X。对于什么样的行业、什么样的企业、通过什么样的方式,才可以达成数据分享的联盟,这是每一个征信企业都要思考的问题。
现在我们介绍了征信误差这个概念。接下来的问题是:如何测量CSE?我们可以精确知道CSE是多少吗?当然不可能。因为在Z*已知的前提下,如果还精确知道了CSE,那等价于精确知道了Z。而如前所述,Z是不可能精确知道的。那么如何评价Z*的误差呢?这是统计学另外一个了不起的创意。它说:如果我们无法知道CSE的精确取值,那么就计算一下他的预期(Expectation)吧。其实细想一下,这不是一个值得特别开心的事情。因为,但凡我们可以知道CSE的精确取值,就没有必要计算他的预期了。之所以用预期的CSE(ECSE,Expected Credit Scoring Error),是因为没有更好的办法了。但是,不管怎样,ECSE应该是一个有用的工具,而且是可以通过模型和相关理论计算出来的。从理论上讲, ECSE可以有很多种不同的定义。例如:绝对误差和均方误差就是两个可能的不同选择。但是,无论如何定义,一个合理的ECSE必须具备一些简单的特征。例如:如果ECSE=0,那么就会有Z*=Z。又例如,只要X的信息越来越多,ECSE会单调下降,但是不会无限接近0。

知道ECSE又怎样?为此,我们再检讨一下王老师芝麻信用分的问题。按照现在的这个理论框架,芝麻采集了一些关于王老师X的信息。因为王老师很少用支付宝,所以X非常有限。这个的后果是,征信估计量Z*=630是一个很不准确的得分。如果我们可以计算他的ECSE,可能是一个很大的数字(例如:50)。这说明,其实630±2*50都是王老师真实信用的合理取值范围。最小可以到530(糟糕透顶),最好可以到730(极其优秀)。王老师,以小人之心,做一个腹黑的推断:可能,为了增加更多更丰富的X,芝麻的信用得分里还会惩罚像王老师这样信息不完备的家伙,而鼓励完成“芝麻任务”,养成“芝麻习惯”的用户。然而,这些都是在增加X,降低ECSE,而无关乎真实的信用。
ECSE这样一个理论框架,对于未来的征信实践有什么建议?我想至少有两个:(1)对于ECSE很大的用户,应该勇敢地说出来,我不了解你,因此对你的信用无法评估。这里的意思是:我不知道你是好人还是坏人,不排除任何一种可能。当然,如果你一定渴望我为你提供一个评估,那么请提供充足的X信息,直到ECSE降到理想的水平。这个方法的好处是容易操作,但是缺点是要求太高。按照这个要求,我相信绝大多数互联网用户能够提供给征信机构的信息是不充分的,是达不到这个标准的。(2)另外一个解决方案就是:我评估了,但是汇报一下ECSE,提示一下用户,我们的评估误差估计会有多大。这样做的优点是:更加科学准确,而且可以覆盖更多的用户。但是缺点是太专业,对于普通用户不好懂。一个更好的做法,也许是提供一个关于Z的区间估计。为此,统计学中的置信区间(或者预测区间)将大有用武之地。不管是哪一种选择,(1)或者(2),如果没有对征信误差的合理管控,我们将看到的是征信泛滥。我们将看到越来越多的企业机构对个人信用指手画脚,而普通用户一脸茫然,非常被动,进而引起愤怒。这对整个征信行业不是好消息。
因此总结一下:要避免征信泛滥,就要准确评估征信误差。咋评价?认真学习统计学理论呗。额,对不起各位,兜了一个很大的圈子,最后的结论是:统计学好,统计学很重要,统计学都没学好,干啥啥不行,吃嘛嘛不香,后果很严重。










